こんにちは,shun(@datasciencemore)です!!
前回までで予測モデリングの全体像がなんとなくつかめたと思います.
今回からは予測モデリングの各STEPについて詳細に説明していきます.
今回は予測モデリングのSTEP1:探索的データ分析についてやっていきます.
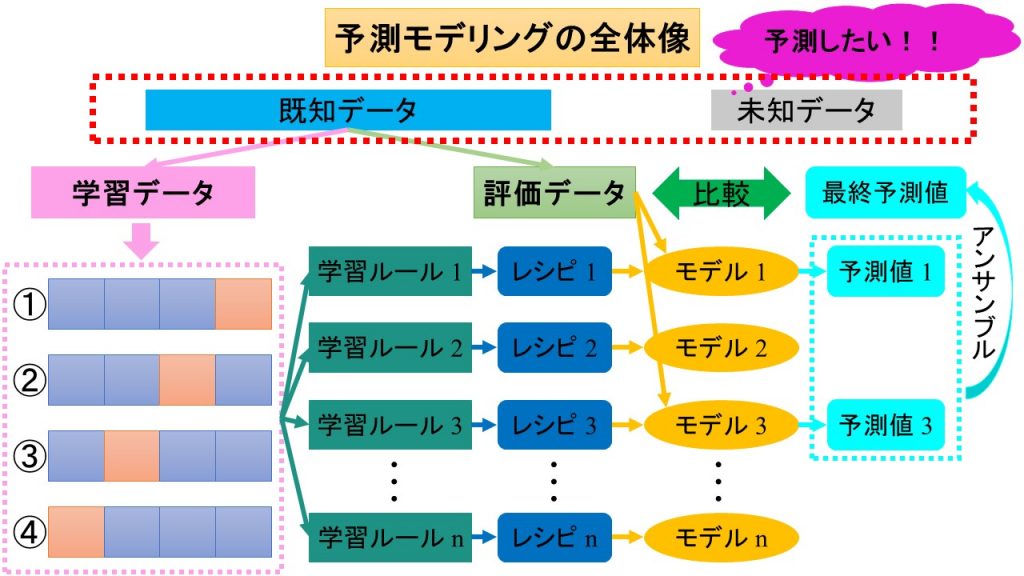
STEP1:探索的データ分析は,図の赤点線枠で囲った部分に該当します.
0.探索的データ分析ってなに??

探索的データ分析っていうのは,予測モデリングの方向性を決めるためにデータの特徴をおおざっぱに把握することだよ!!
探索的データ解析やEDA(Explanatory Data Analysis)とか言ったりもするよ!
予測モデリングと人間の学習プロセスの比較はこちらになります.

STEP1:探索的データ分析は,人間の学習プロセスでは,合格のために様々な情報を集めることに該当します.
我々人間は,合格するために先生とか参考書の情報を色々集めますよね.
STEP1:探索敵データ分析はまさにそれと同様,予測モデリング成功のために色々な情報を集める作業のことです.
こちらの図が探索的データ分析のイメージ図です.

探索的データ分析は,以下のように「1.仮説立案」と「2.合否基準立案」の2つに分類され,さらにそれぞれ細分化されます.
1.仮説立案
①項目確認
②基本統計量算出
③可視化
④仮説作成
2.合否基準立案
①ベースライン算出
②合否基準作成
「1.仮説立案」では,①項目確認〜③可視化をして,データの特徴がおぼろげながらわかった後に,それらの情報をもとに④仮説作成で仮説を作成します.
「2.合否基準立案」では,①でベースライン算出によりベースラインを算出した後に,その情報をもとに②合否基準作成で合否基準を作成します.
そしてこのあとの工程(STEP6:モデル検証)で,作成した仮説や合否基準を確認します.
それでは,詳細にみていきましょう.
今回はデータセットの定番,irisを例にしていきます.
irisはこんな感じのデータです.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# A tibble: 150 x 5 Sepal.Length Sepal.Width Petal.Length Petal.Width Species <dbl> <dbl> <dbl> <dbl> <fct> 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa 7 4.6 3.4 1.4 0.3 setosa 8 5 3.4 1.5 0.2 setosa 9 4.4 2.9 1.4 0.2 setosa 10 4.9 3.1 1.5 0.1 setosa # … with 140 more rows |
Speciesを目的変数,それ以外の列を説明変数とした予測モデリングを考えてみましょう!
1.仮説立案
①項目確認
データの各列が何を示しているのかを明確にします.
それでは,irisの各列を見てみましょう.
Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,Speciesと5列ありますね.
それぞれの列は,以下のような意味となります.
| No. | 列名 | 意味 |
| 1 | Sepal.Length | がく片の長さ(cm) |
| 2 | Sepal.Width | がく片の幅(cm) |
| 3 | Petal.Length | 花弁の長さ(cm) |
| 4 | Petal.Width | 花弁の幅(cm) |
| 5 | Species | あやめの種類 |
No.1~4(青色部分)を説明変数,No.5(赤色部分)を目的変数とすればよさそうですね!!
②基本統計量算出
各列の基本統計量を算出します.
- 平均
- 分散
- データ数
- 欠損値の割合
などを算出します.
irisだとこんな感じです.(Rのパッケージを使用しています.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
─ Data Summary ──────────── Values Name Piped data Number of rows 150 Number of columns 5 _______________________ Column type frequency: factor 1 numeric 4 ________________________ Group variables None ─ Variable type: factor ────────────────────────────────────── skim_variable n_missing complete_rate ordered n_unique top_counts 1 Species 0 1 FALSE 3 set: 50, ver: 50, vir: 50 ─ Variable type: numeric ───────────────────────────────────── skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100 hist 1 Sepal.Length 0 1 5.84 0.828 4.3 5.1 5.8 6.4 7.9 ▆▇▇▅▂ 2 Sepal.Width 0 1 3.06 0.436 2 2.8 3 3.3 4.4 ▁▆▇▂▁ 3 Petal.Length 0 1 3.76 1.77 1 1.6 4.35 5.1 6.9 ▇▁▆▇▂ 4 Petal.Width 0 1 1.20 0.762 0.1 0.3 1.3 1.8 2.5 ▇▁▇▅▃ |
③可視化
データを可視化します.
説明変数と目的変数の相関関係や外れ値からデータの特徴を把握します.
可視化の方法は様々ありますが,個人的に一番使えると思うのは散布図行列です!
散布図行列とは,複数の散布図を行列形式に並べたものです.
ちなみに散布図行列という名前ですが,対角線上にはちゃんとヒストグラム(密度曲線)が並びます.
irisの散布図行列はこんな感じ

傾向が一目瞭然でとてもいいですね!!
④仮説作成
①項目確認〜③可視化で得た情報をもとに仮説を立案します.
例えば
- 体重が大きくなるほど身長は高い.
- 駅から遠くなるほど家賃は低い.
- 借金が多いほどローン審査に合格する可能性は低い.
などなど,分析の目的に応じて様々な仮説が考えることができます.
irisで仮説を立案する場合,①〜③からこんな感じのことが言えそうですね!
- Sepal.Lengh,Sepal.Width,Petal.Lenth,Petal.Widthは,Speciesごとに傾向が異なる.
- Sepal.LenghとSepal.Width,Petal.Lenth,Petal.Widthは,Speciesごとに見ると正の相関がある.
- それぞれの散布図から,Speciesごとにクラスタがある.
以上の3点から,Speciesは,Sepal.Lengh,Sepal.Width,Petal.Lenth,Petal.Widthを使用すれば予測できる可能性が高い.
みたいな仮説が立てられそうです.
仮説は,あくまで仮説なので,この段階であっているかはわからないです.
なので,この段階はそこまで時間をかけないでサクッと終わらせましょう.
経験上,最初に立てた仮説がドンピシャであっているということはないです.
このあとの工程も実施していく過程で立案した仮説の妥当性が徐々に明らかになっていくので,結果に応じて仮説を再度検討するか,先に進むか判断するようにしましょう.
一番やってはいけないことは仮説を持たないでやみくもにデータ分析をすることです.
そんなことをすると時間だけが溶けていきますよ(何度も経験あり笑)
2.合否基準立案
①ベースライン算出
ここでは,データに最低限の前処理をして予測精度を確認します.
その予測結果のことをベースラインと呼びます.
なぜそのようなことをするかというと,以下の点をざっくりと確認するためです.
- 既存のデータで予測ができそうかどうか.
- 予測モデリングの合否基準をどの程度にするか.
ここで予測精度が極端に悪い場合,次の工程に進まないで分析の目的や立案した仮説を見直すべきです.
予測精度が極端に悪い原因は様々考えられますが,経験上,データの品質がものすごく悪いためであることが非常に多いです.
もしデータの品質が悪いのであれば,まずはデータ分析の前にデータの品質を向上させることを考えてください.
予測精度がまずまずであれば,合否基準を作成します.
今回の例で言うと,目的変数がSpeciesとカテゴリなので,ベースラインとして60%の正答率を達成したとしましょう.
Speciesは3つのカテゴリがあるので,60%はまぁまぁ良い成績ということができます.
こんな感じであれば次の②合否基準作成に進んでOKです.
逆に正答率が20%とかであるならば,次の②合否基準作成に進まないで,予測精度が低い原因を考えたほうがいいでしょう.
②合否基準作成
どの程度の予測精度を達成すればいいかを決定します.
目的変数が数値であればRMSEなどが,目的変数がカテゴリであればaccuracyなどが代表的な評価指標です.
また例で考えてみましょう.
前項の「①ベースライン算出」で最低限の前処理で60%の正答率を達成済みです.
ということは,もうちょい真面目に予測モデリングに取り組めば60%よりも良い正答率を達成できそうですね!
という感じに考えて合否基準を
正答率 >= 70% ⇒ OK
正答率 < 70% ⇒ NG
と設定することができますね!
この合否基準は正解はありません.
予測モデリングの対象や目的に応じて,適した合否基準を設定するようにしましょう!
まとめ
今回は,探索的データ分析ということで以下をやりました.
1.仮説立案
①項目確認
②基本統計量算出
③可視化
④仮説作成
2.合否基準立案
①ベースライン算出
②合否基準作成
「1.仮説立案」では,①項目確認〜③可視化をして,データの特徴がおぼろげながらわかった後に,それらの情報をもとに④仮説作成をします.
「2.合否基準立案」では,①でベースライン算出によりベースラインを算出した後に,その情報をもとに②合否基準作成をします.
ベースライン算出時に予測精度が極端に悪かったら,次工程に進まず,分析の目的や立案した仮定を見直しましょう.
ここで作成した仮説や合否基準は,このあとの工程(STEP6:モデル検証)で使うのでお楽しみに!!
今後の分析作業で何をしていくかは次回以降で詳しく見ていきましょう!
それでは,お疲れ様でした!!
です!! 前回までで予測モデリングの全体像がなんとなくつかめたと思います. 今回からは予測モデリングの各STEPについて詳細に説明していきます.){kind=link}